

Schema.org, the collaborative initiative dedicated to promoting structured data markups on the internet, has officially launched a new dataset providing aggregate usage statistics for its extensive vocabulary of terms across the public web. This significant development offers an unprecedented level of transparency into how widely specific schema types are being adopted, showing the number of domains actively utilizing various structured data elements. This move is poised to equip webmasters, SEO professionals, developers, and researchers with invaluable insights into the landscape of semantic web implementation.
The Evolution of Structured Data and Schema.org’s Role
To fully appreciate the gravity of this announcement, it is crucial to understand the foundational role of Schema.org and structured data in the modern web ecosystem. Founded in 2011 by major search engines—Google, Microsoft, Yahoo, and Yandex—Schema.org was created to establish a common set of schemas that webmasters could use to mark up their content. Before Schema.org, describing information on the web in a machine-readable format was fragmented, making it challenging for search engines to accurately interpret the context and meaning of content.
Structured data, at its core, involves adding specific tags and attributes to web content that explicitly describe its nature. For instance, a webpage about a recipe can use schema markup to clearly define ingredients, cooking time, nutritional information, and ratings. A page about an event can specify its date, time, location, and ticket availability. This explicit semantic tagging allows search engines to move beyond keyword matching to a deeper, contextual understanding of the information presented.
The primary benefit of implementing structured data is its ability to enhance search engine visibility and user experience. When search engines understand content more thoroughly, they can present it in richer, more engaging formats directly within search results. These "rich snippets" can include star ratings, product prices, event dates, author information, and more, making a webpage stand out and often leading to higher click-through rates. Beyond rich snippets, structured data fuels features like Knowledge Panels, carousels, and voice search results, becoming an indispensable component of an effective digital strategy.

Over the past decade, Schema.org has grown exponentially, continuously expanding its vocabulary to cover an ever-widening array of entities and relationships, from basic types like Person and Organization to highly specific ones like MedicalCondition and Course. Despite its widespread adoption and acknowledged importance, a significant challenge for the community has been the lack of comprehensive, public data on the actual usage patterns of these schema types. While anecdotal evidence and individual tool reports existed, a unified, authoritative source detailing the prevalence of specific schema terms across the vast expanse of the public web remained elusive—until now.
Unveiling the Usage Statistics Dataset: A Deep Dive
On June 4, 2026, Schema.org formally announced the availability of its new aggregate usage statistics dataset. In a blog post, the organization stated, "we are pleased to share a new dataset providing aggregate usage statistics for Schema.org terms across the public web." This release marks a pivotal moment, offering a data-driven lens into the semantic web.
The dataset is designed with several key characteristics to ensure its utility and accuracy:
- Monthly Updates: The statistics are refreshed on a monthly basis, providing a consistent and relatively current snapshot of adoption trends. This frequency allows for tracking changes over time without being overly sensitive to daily fluctuations.
- Domain-Level Aggregation: The data is aggregated at the domain level, meaning it indicates how many unique domains are using a specific schema type, rather than counting every instance of the markup within a single domain. This approach offers a broad overview of adoption breadth across the web.
- Popularity Range Buckets: Instead of providing exact numbers, the usage statistics are presented in "popularity range buckets." Schema.org clarified its rationale for this approach, stating, "This approach helps filter daily noise while highlighting meaningful adoption trends for researchers and toolmakers." These buckets might categorize usage into ranges like "millions of domains," "hundreds of thousands," "tens of thousands," and so forth, offering a clear sense of scale without revealing granular, potentially sensitive data.
- Accessibility: The statistics are seamlessly integrated directly onto the individual documentation pages for each schema type on Schema.org. This means that when a user navigates to
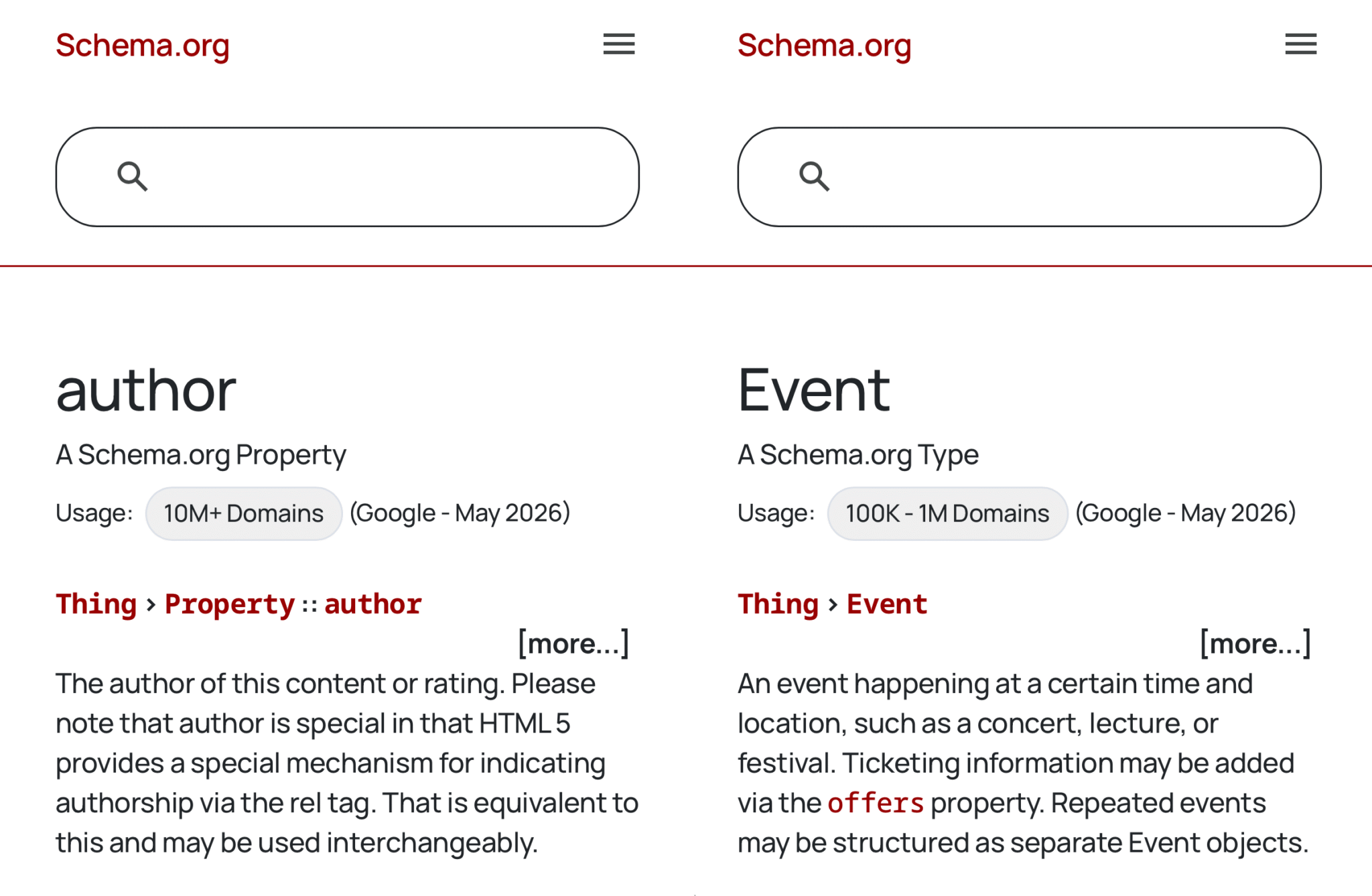
schema.org/authororschema.org/Event, they will immediately see the usage data prominently displayed towards the top of the page. Furthermore, more detailed information and potentially raw data are made available via GitHub, catering to developers and researchers who require deeper analysis capabilities.
For example, navigating to the author schema page (https://schema.org/author) or the event schema page (https://schema.org/Event) now reveals a clear indication of their respective adoption rates. A screenshot shared by Schema.org illustrates this, showing these statistics positioned near the top of the schema definition, making them readily accessible for anyone exploring the vocabulary. This direct integration streamlines the process for webmasters and developers to assess the prevalence of a given schema type as they consider its implementation.
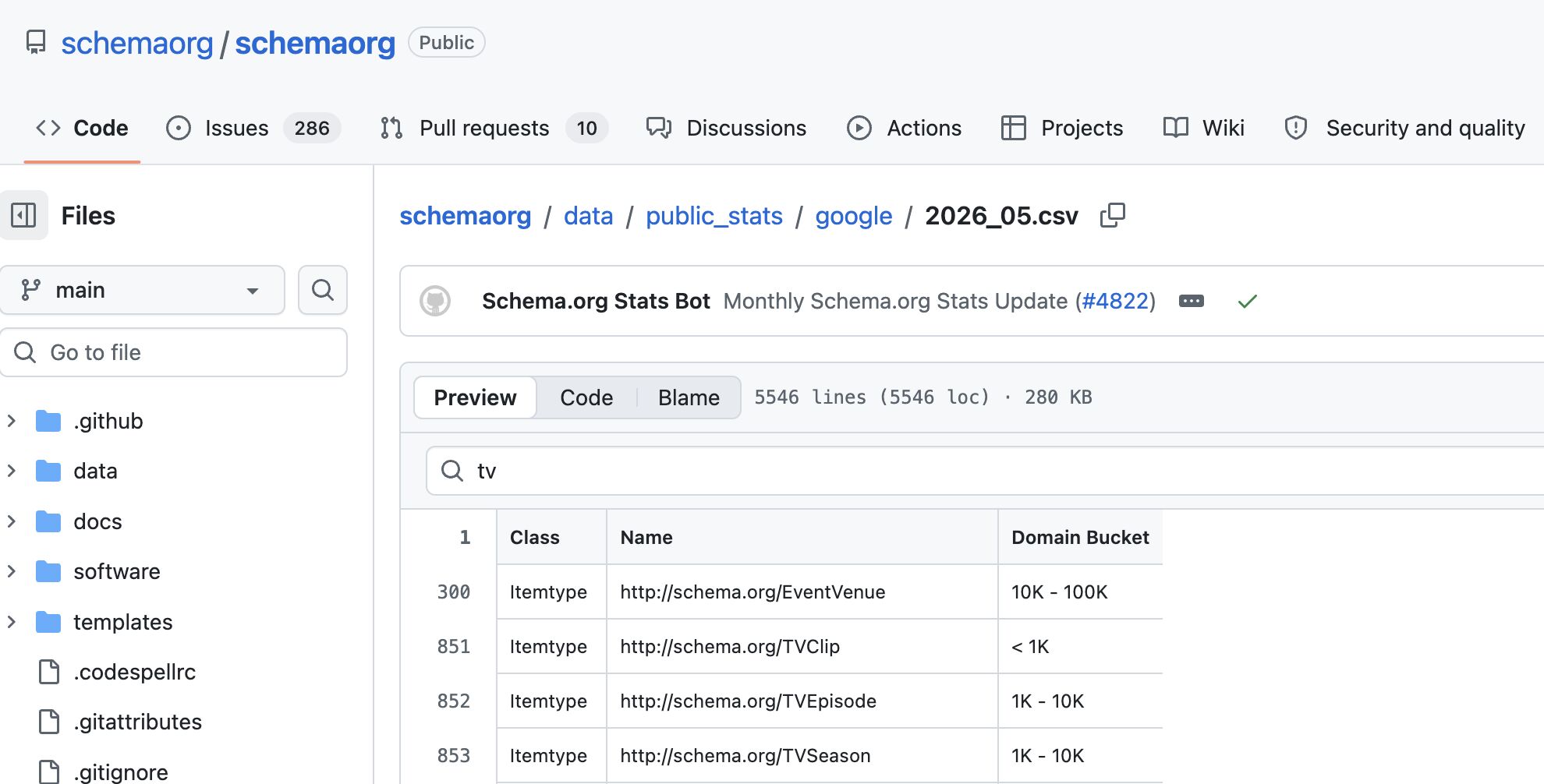
The comprehensive documentation page, schema.org/docs/usage_stats.html, provides further details on the methodology, scope, and interpretation of the dataset. This resource is essential for users seeking to fully understand the nuances of the data and leverage it effectively. The availability of the data on GitHub further underscores Schema.org’s commitment to transparency and community involvement, allowing advanced users to integrate this information into their own tools and analyses.
Transformative Implications Across Industries
The release of Schema.org’s aggregate usage statistics dataset carries significant implications for various stakeholders within the digital landscape.
For SEO Professionals and Marketers:
This dataset is a game-changer for search engine optimization specialists. Historically, SEOs have relied on best practices, search engine guidelines, and third-party tools to infer the importance and impact of structured data. Now, they have direct, authoritative data to inform their strategies:
- Strategic Prioritization: Knowing which schema types are widely adopted allows SEOs to prioritize their implementation efforts. If a critical schema type for a client’s industry (e.g.,
Productfor e-commerce,Recipefor food blogs) shows high adoption, it strengthens the case for immediate implementation to maintain competitive parity. Conversely, identifying less-adopted but highly relevant schemas could present an opportunity for early adoption to gain a competitive edge. - Justifying Investment: Presenting data on widespread adoption can be a powerful tool for convincing development teams or management to allocate resources for structured data implementation. "Millions of domains are using
Reviewschema" is a much stronger argument than "Google recommends it." - Competitive Analysis: While not providing competitor-specific data, the aggregate statistics offer a benchmark. If an SEO sees that
LocalBusinessschema is used by hundreds of thousands of domains, they can infer that many competitors are likely using it, prompting a review of their own local SEO strategy. - Trend Identification: The monthly updates will allow SEOs to spot emerging trends in structured data usage. A sudden increase in adoption for a specific schema type might signal a new emphasis from search engines or a growing industry standard, prompting proactive adjustments.
For Web Developers and Toolmakers:
The dataset provides critical intelligence for those building the tools and platforms that power the web:
- CMS and Plugin Development: Developers of Content Management Systems (CMS) and associated plugins (e.g., for WordPress, Shopify) can use this data to prioritize which schema types to integrate or enhance. Supporting the most widely used schemas ensures their products remain relevant and valuable to users.
- Validation Tools: Makers of structured data validation tools can refine their offerings, potentially highlighting schema types that are gaining traction or providing more targeted recommendations based on usage patterns.
- API Integration: The availability of data via GitHub encourages the development of third-party applications that can pull and analyze this information, creating new services for schema analysis, monitoring, and reporting.
- Standardization Efforts: By understanding which schemas are broadly accepted, developers can contribute to a more standardized and interoperable web, reducing fragmentation in data representation.
For Researchers and Academics:
This dataset opens new avenues for academic inquiry into the semantic web:
- Empirical Studies: Researchers can conduct large-scale empirical studies on the evolution of structured data usage, its correlation with search engine rankings, and its impact on information retrieval.
- Understanding Web Semantics: The data provides a quantitative basis for understanding how websites describe their content over time, offering insights into the broader trends of web semantics.
- Future Development: Academic research can leverage this data to inform future directions for Schema.org and other semantic web initiatives.
For Schema.org Itself:
The dataset serves as a crucial feedback mechanism for the organization:
- Measuring Impact: It allows Schema.org to quantify the success of its standardization efforts and understand the real-world impact of its vocabulary.
- Prioritizing Development: Insights into adoption rates can help guide the development of new schema types or the refinement of existing ones, focusing resources on areas of highest utility and need.
- Community Engagement: Providing this data fosters greater transparency and encourages more informed participation from the global web community.
Challenges, Limitations, and Future Outlook
While the release of this dataset is a monumental step forward, it is important to acknowledge certain inherent challenges and limitations. The decision to present data in "popularity range buckets" rather than exact numbers, while beneficial for filtering noise and highlighting trends, might be seen as a limitation by those requiring highly granular statistics for very specific analyses. Furthermore, the aggregation at the domain level means that the data does not differentiate between a domain using a schema type once and a domain using it hundreds of times, focusing on breadth rather than depth of implementation per domain.
Another aspect of interest is the underlying methodology for data collection. While Schema.org is a collaborative effort involving major search engines, the precise mechanisms by which this aggregate data is compiled from the vast index of the public web are detailed in the documentation, but understanding the specific crawl data sources and processing techniques is crucial for thorough interpretation. Monthly updates are valuable, but in the fast-paced digital world, even a month can see significant shifts, meaning the data always represents a snapshot rather than real-time usage.
Despite these points, the overall sentiment across the digital marketing and development communities is overwhelmingly positive. The data provides a robust foundation for more informed decision-making and strategic planning.
Looking ahead, this initial release could pave the way for even more sophisticated insights. Future iterations of the dataset might include more granular data points, perhaps offering segmentations by industry or geographic region, or even more advanced filtering capabilities. The integration of this data into various third-party SEO tools and CMS platforms is highly anticipated, promising to embed these crucial insights directly into daily workflows.
In an increasingly complex and AI-driven web, where machines are expected to understand, process, and generate content, the role of structured data becomes even more paramount. Schema.org’s continued commitment to providing transparency and tools for understanding its ecosystem reinforces its position at the forefront of semantic web development. This new usage statistics dataset is not just a collection of numbers; it is a powerful catalyst for driving more intelligent, data-informed, and standardized practices across the entire public web. The future of the semantic web is now more visible, and its evolution can be tracked with unprecedented clarity, empowering stakeholders to build a more understandable and interconnected digital world.


{kind=link}